Anonimatron: Overview
 In every software project, there comes a time where a bug pops up, nobody knows how to reproduce it, and somebody says "I know, let's test this against a copy of the production database". Even with the best intentions, once production data leaves the production machine with all its safeguards it becomes really hard to do access control on that data.
In every software project, there comes a time where a bug pops up, nobody knows how to reproduce it, and somebody says "I know, let's test this against a copy of the production database". Even with the best intentions, once production data leaves the production machine with all its safeguards it becomes really hard to do access control on that data.
Most of the time, it's not even needed to have that data. Developers just need a data set which resembles the production scenario close enough. Some brave souls have mixed succes with data generators, but those generators usually are tedious to maintain and die a slow death under the pressure of the daily grind.
In some ambitious projects automated integration testcases are built on top of the data which was inserted by the data generators. As the generators die, so die the tests. If you recognize this pattern, Anonimatron might be the answer for you.
So let's say you're working on release 5 of a big webshop, and because of the succes of the shop, it runs into performance problems. There's no time or budget to build a data generator, and before you can say no, you have a copy of the production data on some development server, containing the creditcard data of your customers. What do you do?
This is where Anonimatron comes in. Anonimatron can de-personalize or anonymize your data for you, give you total control over what gets anonymized, and how, and thinks of data types as "color" or "address" instead of "int" and "String". Here's how that works:
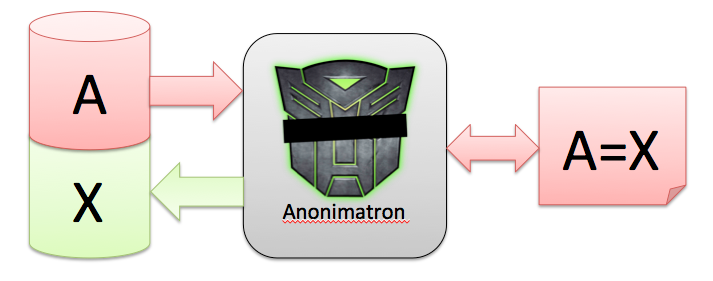
For every distinct, unique value A, Anonimatron creates a replacement value X, and writes that back to the database. It stores the A=X relation in a Synonym, and consistently applies those Synonyms throughout all tables in the database.
By using synonyms, Anonimatron makes sure that your database is still statistically roughly the same as before anonymization, and also makes sure that if you have two tables with a "lastname" column, matching records will actually still match.
Anonimatron (optionally) stores these synonyms for later use, so it can be consistent between different runs. New production data? No problem. Load it, tell Anonimatron to use the old synonyms, and the old data will be Anonymized exactly the same as the last time. Only new records will generate new synonyms, which of course will be added to the synonym file for the next run.
This feature also enables you to write testscripts based on anonymized production data. Your scripts will not easily break, because new production copies are anonymized very consistently.
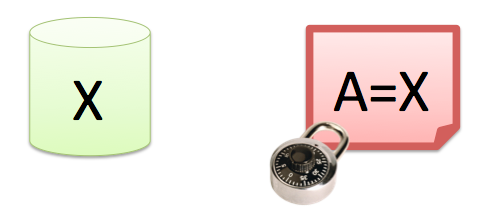
After the anonymization process, the private data will be in the synonym file. This file needs to be put in a (very) safe place, and only the people that import production data and run Anonimatron should be able to access this file.
After anonymization, developers can access the database without immediately being exposed to private addresses of customers, bank accounts, or whatnot. Of course this all depends on what you tell Anonimatron to do, and what to anonymize.
Remember, with great power comes great responsibility. Try to stay away from customer data as much as you can, and handle it with deep respect when you get it, delete it or depersonalize it as soon as you can. Use Anonimatron wisely.